I’m just getting back from a nice trip to the US where I attended the Academic Data Science Alliance leadership summit and before that the Web Conference 2023 (WWW 2023) in Austin, Texas. This is the premier academic conference on the Web. The conference organisation was led by two friends and collaborators Dr. Juan Sequeda and Dr. Ying Ding. They did a fantastic job with the structure, food, keynotes (e.g. ACM Turing Award Winner Bob Metcalfe) and who can not give two thumbs up to BBQ and Austin Live Music. The last in-person Web Conference I was at was in 2018 in Lyon, so it was good to be back and to catch-up with a lot of folks in the community.
Provenance Week 2023
The main reason that I was at Web Conf was for Provenance Week 2023, which was collocated, It’s a bit of misnomer – since it was a special two day event. In the past, we’ve done this as a whole week as a separate event but coming out of the pandemic, the steering committees felt that collocating would be better. There were about 20 attendees. I was presenting the work we’ve done led by Stefan Grafberger on on mlinspect and use-cases for provenance and end-to-end machine learning. It was also nice to meet Julia Stoyanovich our co-author on this work for the first time in person. I also was very happy to celebrate the 10th anniversary of the W3C Prov provenance recommendation.
For that we organised a panel, with the other co-chair of the working group (Prof. Luc Moreau) and two co-editors (Prof. Paolo Missier, Prof. Deborah McGuinness). All three are also leaders in provenance research. We also were joined by Bryon Jacob – CTO of data.world. It was excellent to have Bryon there as data.world is a heavy user of PROV and wasn’t involved in the standardisation effort. He commented on how from his perspective the spec was really usable. We discussed the up take of PROV. The panel felt that uptake has been good with demonstrable impact use but the committee members were hoping for more. The fact that it is often used within systems or as a frame of reference (e.g. HL7 FHIR) means that it’s not as widely known as hoped. I think the panel did agree that provenance is needed now more than ever. For example, Bryon focused on data governance where data.world employs provenance. It’s becoming critical to know where data comes from to understand the broader data estate but also to deal with legal issues related to provenance. Additionally, generative AI is placing further demands on provenance. Here, I would point to work being pushed by Adobe specifically the Content Authenticity Initiative and their Firefly tools + LLM. Overall, the panel reinforced to me the need for interoperable provenance and the role that PROV has played in providing a reference point.
Beyond the panel, I took 3 things from the workshop:
- The intersection of provenance and data science/AI pipelines is promising. There’s a clear demand for it (and broadly ML-ops) but it also provides particular constraints that make designing provenance systems (somewhat) easier. You can make some assumptions about the kind of frameworks being used and the targeted applications are not too specific but also not completely general purpose. There’s also space for empirical insights to drive system development. This intersection was being investigated not only in our work mentioned above. For example, in Vanessa Braganholo’s keynote on the noWorkflow provenance system, I thought their work on analysing 1.4 million Juypter Notebooks was cool. I’d also mention a number of other systems discussed at the workshop including Data Provenance for Data Science and Vizier and a new system presented at the workshop focused on deep learning and data integration. Lastly, much of this work also touches on the importance of data cleaning in data science. Here, I liked the work presented by Bertram Ludäscher on using prospective provenance to document data cleaning and reuse such pipelines.
- Provenance-by-design – I found this notion introduced by Luc in his paper interesting. Instead of trying to retrofit provenance gathering to applications either through instrumentation or logging, one should first design what provenance to capture and then integrate the business logic with that. In some sense, this is thinking about your workflow but also what you need to report. I can imagine this being beneficial in regulated environments such as banking or in sustainability applications as described in the paper above.
- Interesting tasks for provenance in databases: I liked a couple of different papers that used the provenance functionality of database systems (i.e. provenance polynomials) for various tasks. For example, the work by Tanja Auge on using provenance to help create sharable portions of databases; or the work on expanding the explanation of queries to including contextual information (+10 points for using basketball examples); or the use of this functionality to support database education as presented by Sudeepa Roy in her keynote; or even to support provenance for SHACL.
- Provenance as a measure for data value: I really enjoyed Boris Glavic’s keynote on relevance-based data management. In particular, the idea of determining relevance of data and using that to understand which data has value and which doesn’t. Also check out his deck if you want a checklist for doing a keynote 😀
-

Overall, I think the workshop was a success. It was good to catch-up with old friends but also it was nice to hear from the younger scholars there that they felt connected to the community. Thanks to Yuval and Daniel for organising and also giving plenty of time for discussion during the workshop.
In addition to provenance week, there were a number of things that caught my eye at the conference. First, the Web Conf remains a top tier conference that’s challenging to get into. With 1891 submissions and acceptance rate of 19% in the research track. Given the quality of the conference there is an increasing number of submissions that maybe don’t really belong to the venue. Hence, I thought it was a great initiative by the organisers to really focus on defining what makes a web conference paper:

Generative AI
There was a lot of background discussion going on about generative AI and the implications for the web. Here, I would point to three of the keynotes. From the perspective of misinformation and the potential to expand that through generative AI, the keynote by David Rand specifically addressed misinformation and how to combat it from a social science perspective. More broadly Barbara Poblete’s advocated forcefully for inclusion in the development of AI systems and LLMs based on her research on developing social media and AI systems in Chile. Bob Metcalfe in his Turning Award speech discussed the idea of an engineering mindset and embracing the problems and opportunities of new technology. In his case, it was the internet, but why not for generative AI?
From the research talks, I liked the work on creating a pretrained knowledge graph model that can then be used by prompting. I also liked the work on doing query log analysis on prompt logs from users of generative models to help understand user intent. This is a pretty interesting analysis over quite a lot of prompts:

Generative AI also provides a new source of knowledge. A nifty example of this was from The Creative Web track where Bhavya et al. mined and importantly assessed creative analogies from GPT-3. Also there was nice example of extracting cultural common sense knowledge and the strengths and weaknesses of LLMs and knowledge graphs.
Wikidata
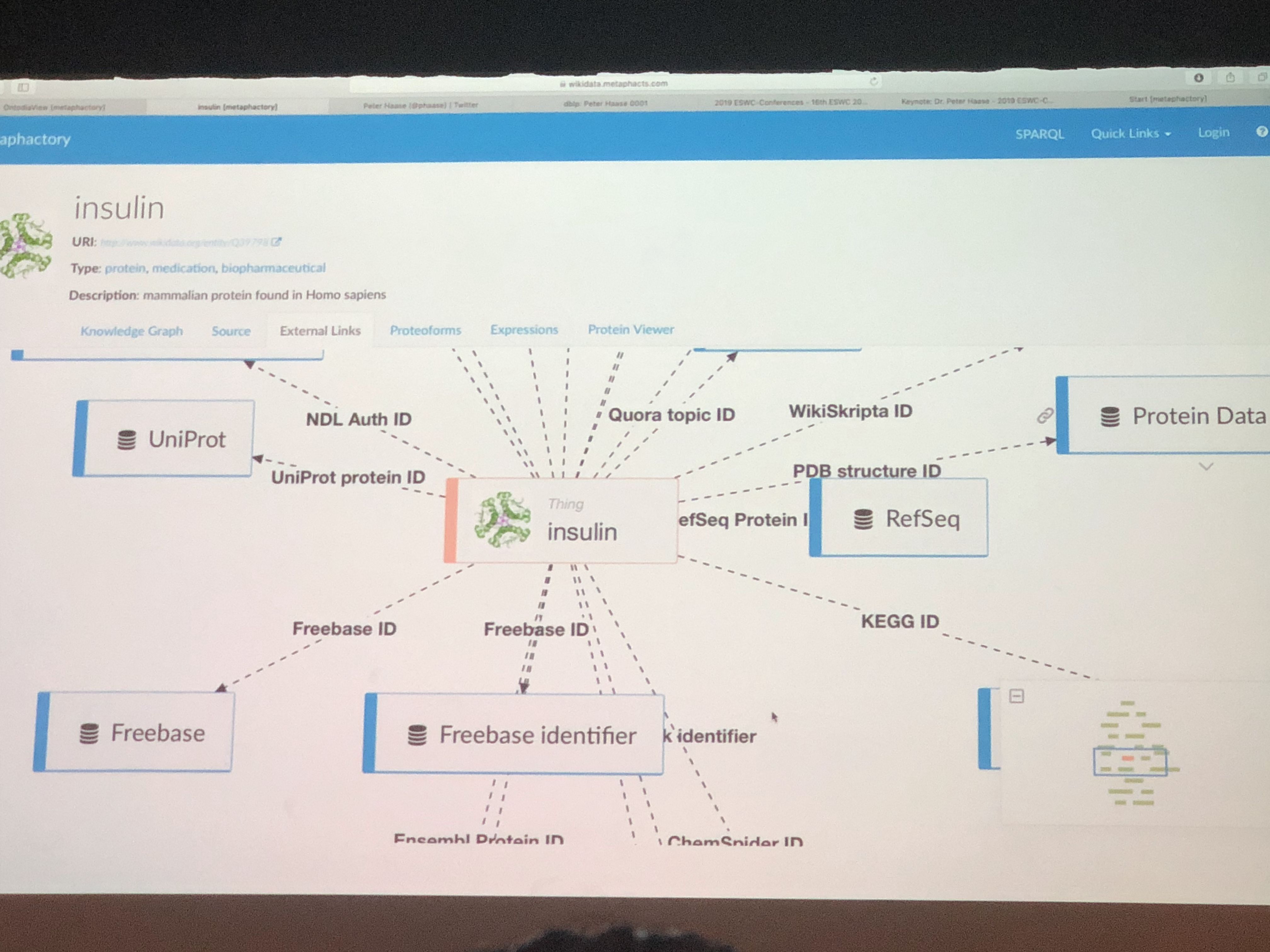
I spent some time in the history of the web sessions. This was really fun. Here, I would particularly call out the really great talk about the creation of Wikidata by Denny Vrandečić. It’s an amazing success story. Definitely checkout the whole talk on YouTube.

More broadly there were a number of useful talks about enriching Wikidata. Specifically, about completing Wikidata tables using GPT-3 and using Wikidata to seed an information extractor from the web. This later paper is interesting for me because it uses QA based information extraction with an LLM a technique that we’ve been researching heavily. What I thought was interesting is that they do the QA directly on the HTML source itself. They use Wikidata to fine tune this extraction model.
Taxonomies are back and a thought on KG completion
There were quite a number of papers on building taxonomies including the student best paper award. Pointers:
- A Single Vector Is Not Enough: Taxonomy Expansion via Box Embeddings
- TaxoComplete: Self-Supervised Taxonomy Completion Leveraging Position-Enhanced Semantic Matching
- Hierarchy-Aware Multi-Hop Question Answering over Knowledge Graphs
In general, automatically creating hierarchies are useful for browsing and also useful for computer vision problems. Whether these papers are truly tackling taxonomies or just building hierarchies was a discussion we were having in the coffee break.
More broadly in the sessions where these papers were presented, there were a lot of papers on link prediction/node classification in knowledge graphs whether it was with metapaths; tackling temporal knowledge graphs or using multiple modalities. I’ve done work on this task myself but it would be nice to see different topics and more importantly different evaluation datasets. As Denny noted, Freebase shutdown in 2014 and we’re still doing evaluation on it
Overall, I think the Web as an evolving platform still presents some of the most exciting research challenges in CS. Austin was a great place to have it. Kudos to the team and the community.

Random thoughts
- Amsterdam as a hub of information exchange.
- Knowledge graphs are for people: Zachary Elkins – Concept Regulation in the social sciences and the Constitute Project
- Optimise the performance of python web apps.
- I admit I used a scooter to get around Austin.
- Weedle: A dashboard for data centric NLP- hope this is available soon.
- Lots of discussion about remote talks, the viability of conferences going forward, community culture… but … personally I just get so much more from in-person.
- The Web Data Commons Schema.org Data Set Series is a great resource.
- The web is an application platform. Is that a good thing? Would be fun to debate this with Steven Pemberton. I’d probably lose but still 😀
- The Mexican 🌮 and BBQ 🍖 are really really good in Austin. But you probably already know that.





 Good job!
Good job!




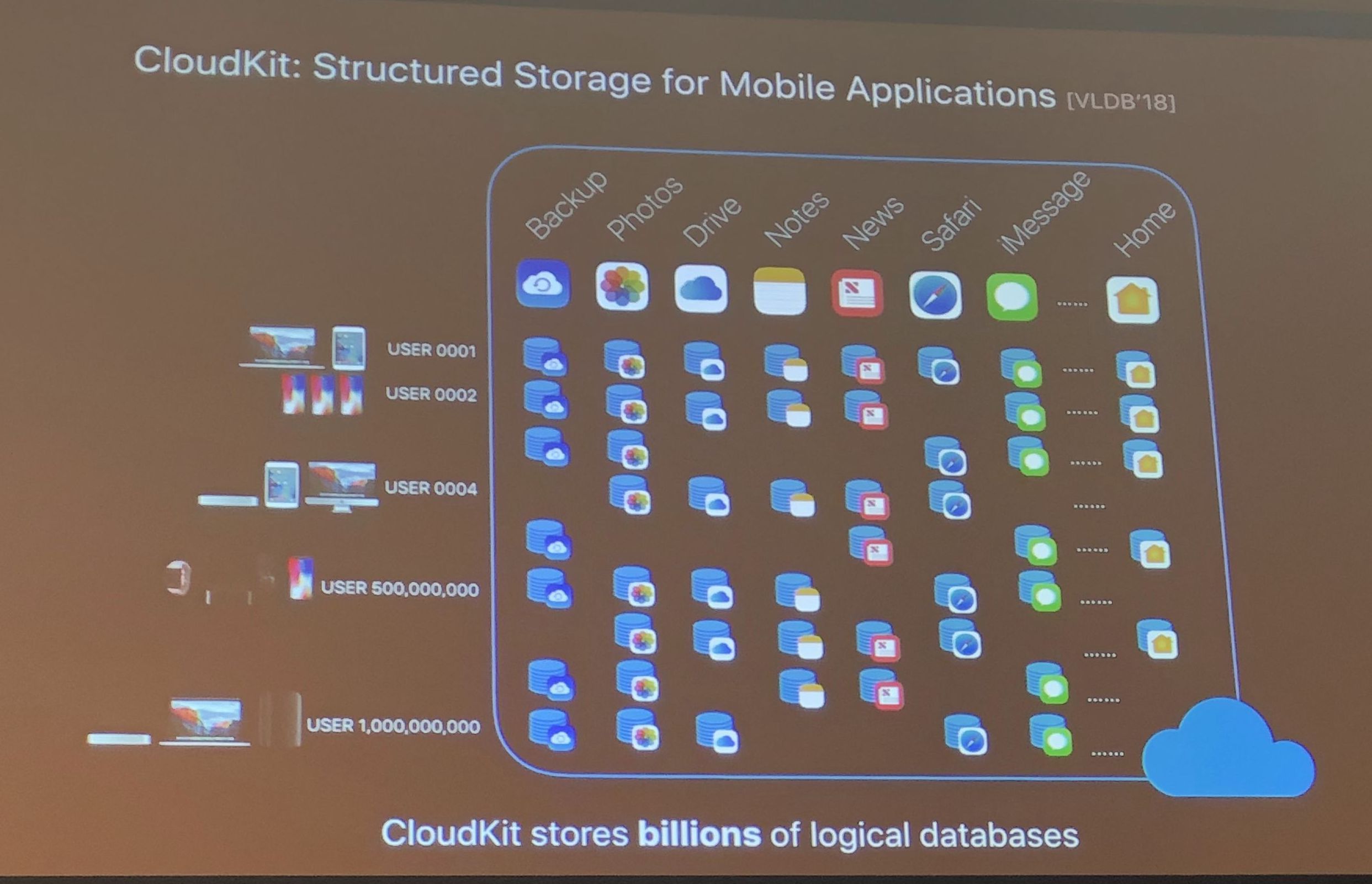
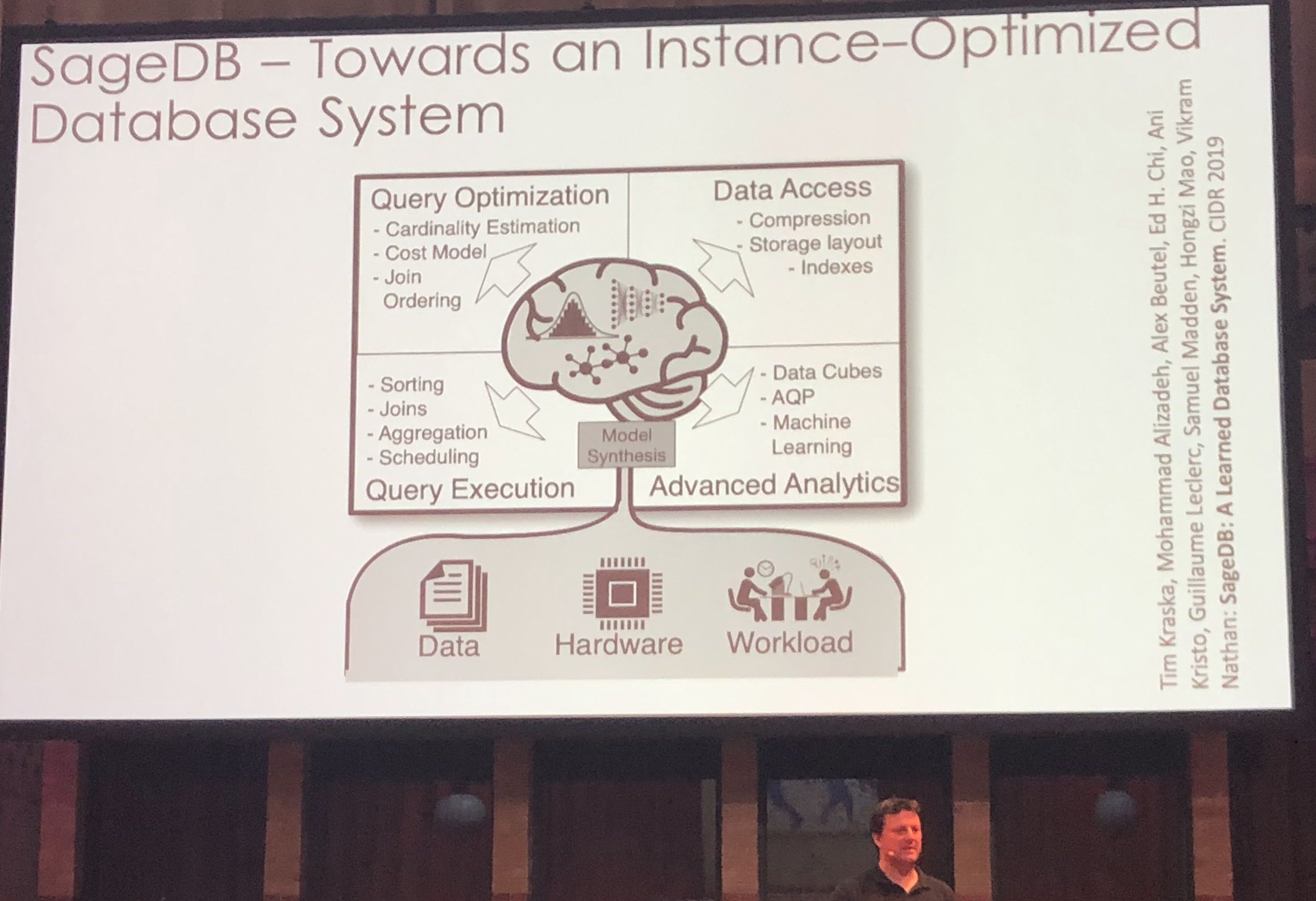 It was quite good, I hope they put the slides up somewhere. The key notion for me is this idea of instance optimality: by using machine learning we can tailor performance to specific users and applications whereas in the past this was not cost effective because the need for programmer effort. They suggested 4 ways to create instance optimized algorithms and data structures:
It was quite good, I hope they put the slides up somewhere. The key notion for me is this idea of instance optimality: by using machine learning we can tailor performance to specific users and applications whereas in the past this was not cost effective because the need for programmer effort. They suggested 4 ways to create instance optimized algorithms and data structures: