Trip Report: AKBC 2019
About two weeks ago, I had the pleasure of attending the 1st Conference on Automated Knowledge Base Construction held in Amherst, Massachusetts. This conference follows up on a number of successful workshops held at venues like NeurIPS and NAACL. Why a conference and not another workshop? The general chair and host of the conference (and he really did feel like a host), Andrew McCallum articulated this as coming from three drivers: 1) the community spans a number of different research areas but was getting its own identity; 2) the workshop was outgrowing typical colocation opportunities and 3) the motivation to have a smaller event where people could really connect in comparison to some larger venues.
I don’t know the exact total but I think there was just over 110 people at the conference. Importantly, there were top people in the field and they stuck around and hung out. The size, the location, the social events (a lovely group walk in the forest in MA), all made it so that the conference achieved the goal of having time to converse in depth. It reminded me a lot of our Provenance Week events in the scale and depth of conversation.
Oh and Amherst is a terribly cute college town:

Given that the conference subject is really central to my research, I found it hard to boil down everything into a some themes but I’ll give it a shot:
- Representational polyglotism
- So many datasets so little time
- The challenges of knowledge (graph) engineering
- There’s lots more to do!
Representational polyglotism
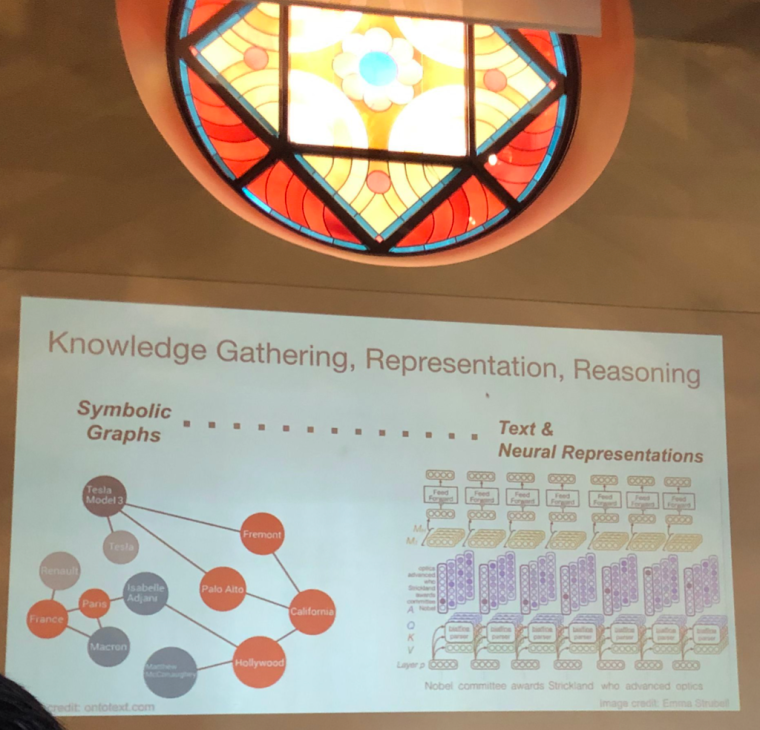
One of the main points that came up frequently both in talks and in conversation was around what one should use as representation language for knowledge bases and for what purpose. Typed graphs have clearly shown their worth over the last 10 years but with the rise of knowledge graphs in a wide variety of industries and applications. The power of the relational approach especially in its probabilistic form was shown in excellent talks by Lise Getoor on PSL and by Guy van den Broeck. For efficient query answering and efficiency in data usage, symbolic solutions work well. On the other hand, the softness of embedding or even straight textual representations enables the kind of fuzziness that’s inherent in human knowledge. Currently, our approach to unify these two views is often to encode the relational representation in an embedding space, reason about it geometrically, and then through it back over the wall into symbolic/relational space. This was something that came up frequently and Van den Broek took this head on in his talk.
Then there’s McCallum’s notion of text as a knowledge graph. This approach was used frequently to different degrees, which is to be expected given that much of the contents of KGs is provided through information extraction. In her talk, Laura Dietz, discussed her work where she annotated the edges of a knowledge graph with paragraph text to improve entity ranking in search. Likewise, the work presented by Yejin Choi around common sense reasoning used natural language as the representational “formalism”. She discussed the ATOMIC (paper) knowledge graph which represents a crowed sourced common sense knowledge as natural language text triples (e.g. PersonX finds ___ in the literature). She then described transformer based, BERT-esque, architectures (COMET: Commonsense Transformers for Knowledge Graph Construction) that perform well on common sense reasoning tasks based on these kinds of representations.
The performance of BERT style language models on all sorts of tasks, led to Sebastian Riedel considering whether one should treat these models as the KB:
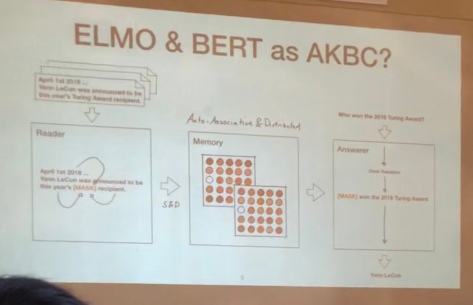
It turns out that out-of-the box BERT performs pretty well as a knowledge base for single tokens that have been seen frequently by the model. That’s pretty amazing. Is storing all our knowledge in the parameters of a model the way to go? Maybe not but surely it’s good to investigate the extent of the possibilities here. I guess I came away from the event thinking that we are moving toward an environment where KBs will maintain heterogenous representations and that we are at a point where we need to embrace this range of representations to produce results in order face the challenges of the fuzzy. For example, the challenge of reasoning:
or of disagreement around knowledge as discussed by Chris Welty:

So many datasets so little time
Progress in this field is driven by data and there were a lot of new datasets presented at the conference. Here’s my (probably incomplete) list:
- OPIEC – from the makers of the MINIE open ie system – 300 million open information extracted triples with a bunch of interesting annotations;
- TREC CAR dataset – cool task, auto generate articles for a search query;
- HAnDS – a new dataset for fined grained entity typing to support thousands of types;
- HellaSwag – a new dataset for common sense inference designed to be hard for state-of-the-art transformer based architectures (BERT);
- ShARC – conversational question answering dataset focused on follow-up questions
- Materials Synthesis annotated data for extraction of material synthesis recipes from text. Look up in their GitHub repo for more interesting stuff
- MedMentions – annotated corpora of UMLs mentions in biomedical papers from CZI
- A bunch of datasets that were submitted to EMNLP so expect those to come soon – follow @nlpmattg.
The challenges of knowledge (graph) engineering
Juan Sequeda has been on this topic for a while – large scale knowledge graphs are really difficult to engineer. The team at DiffBot – who were at the conference – are doing a great job of supplying this engineering as a service through their knowledge graph API. I’ve been working with another start-up SeMI who are also trying to tackle this challenge. But this is still complicated task as underlined for me when talking to Francois Scharffe who organized the recent industry focused Knowledge Graph Conference. The complexity of KG (social-technical) engineering was one of the main themes of that conference. An example of the need to tackle this complexity at AKBC was the work presented about the knowledge engineering going on for the KG behind Apple’s Siri. Xiao Ling emphasized that they spent a lot of their time thinking about and implementing systems for knowledge base construction developer workflow:
Thinking about these sorts of challenges was also behind several of the presentations in the Open Knowledge Network workshop: Vicki Tardif from the Google Knowledge Graph discussed these issues in particular with reference to the muddiness of knowledge representation (e.g. how to interpret facets of a single entity? or how to align the inconsistencies of people with that of machines?). Jim McCusker and Deborah McGuinness’ work on the provenance/nanopublication driven WhyIs framework for knowledge graph construction is an important in that their software views a knowledge graph not as an output but as a set of tooling for engineering that graph.
The best paper of the conference Alexandria: Unsupervised High-Precision Knowledge Base Construction using a Probabilistic Program was also about how to lower the barrier to defining knowledge base construction steps using a simple probabilistic program. Building a KB from a single seed fact is impressive but then you need the engineering effort to massively scale probabilistic inference.
Alexandra Meliou’s work on using provenance to help diagnose these pipelines was particularly relevant to this issue. I have now added a bunch of her papers to the queue.
There’s lots more to do
One of the things I most appreciated was that many speakers had a set of research challenges at the end of their presentations. So here’s a set of things you could work on in this space curated from the event. Note these may be paraphrased.
- Laura Dietz:
- General purpose schema with many types
- High coverage/recall (40%?)
- Extraction of complex relations (not just triples + coref)
- Bridging existing KGs with text
- Relevant information extraction
- Query-specific knowledge graphs
- Fernando Pereira
- combing source correlation and grounding
- Guy van den Broeck
- Do more than link predication
- Tear down the wall between query evaluation and knowledge base completion
- The open world assumption – take it seriously
- Waleed Ammar
- Bridge sentence level and document level predictions
- Summarize published results on a given problem
- Develop tools to facilitate peer review
- How do we crowd source annotations for a specialized domain
- What are leading indicators of a papers impact?
- Sebastian Riedel
- Determine what BERT actually knows or what it’s guessing
- Xian Ren
- Where can we source complex rules that help AKBC?
- How do we induce transferrable latent structures from pre-trained models?
- Can we have modular neural networks for modeling compositional rules?
- Ho do we model “human effort” in the objective function during training?
- Matt Gardner
- Make hard reading datasets by baking required reasoning into them
Finally, I think the biggest challenge that was laid down was from Claudia Wagner, which is how to think a bit more introspectively about the theory behind our AKBC methods and how we might even bring the rigor of social science methodology to our technical approaches:
I left AKBC 2019 with a fountain of ideas and research questions, which I count as a success. This is a community to watch. AKBC 2020 is definitely on my list of events to attend next year.
Random Pointers
- Word Embeddings 6 years later – if you use embeddings read this. From Anna Rogers.
- A Survey of Semantic Parsing
- Is Winter Coming?
- The ambiguity of PDF
- NLP Highlights Podcast
- Very exciting work about integrating software and models into knowledge graphs. See https://models.mint.isi.edu/my-about which was presented by Daniel Garijo
- Yummy – FoodKG
- Good to meet Samuel Klein in person! I think we’re getting to a point where we can put the subjectivity into distributed knowledge graphs (the overlay!)
- Check out the Julia Lane led Coleridge Initiative on improving social science research data search through knowledge graphs.
