Trip Report: WWW 2015
Last week I was in Florence Italy for the 23rd International World Wide Web Conference (WWW 2015). This is the leading computer science conference focused on web technology writ large. It’s a big conference – 1400 attendees this year. WWW is excellent for getting a good bearing on the latest across multiple subfields in computer science. Another way to say it is that I run into friends from the semantic web community, NLP community, data mining community, web standards community, the scholarly communication community, etc.. I think on the Tuesday night I traversed four different venues hanging out with various groups.
This is the first time since 2010 that I attended WWW. It was good to be back. I was there the entire week so there was a ton but I’ll try to boil what I saw down into 3 takeaways. But first…
What was I doing there?
First, was that I co-authored a research track paper with Marcin Wylot and Philippe Cudré-Mauroux of the eXascale Infolab (cool name) on Executing Provenance Queries over Web Data (slides, paper). We showed that because of the highly selective nature of provenance on the web of data, we can actually improve query performance within a triple store. I was super happy to have this accepted given the ~14%! acceptance rate.
Second, I gave the opening talk of the Semantics, Analytics, Visualisation: Enhancing Scholarly Data (SAVE-SD) workshop. I discussed the current state of scholarly productivity and used the notion of the burden of knowledge as a motivation for knowledge graphs as a mechanism to help increase that productivity. I even went web for my slides.
Continuing on the theme of knowledge graphs, I participated on a panel in the industry track around knowledge graphs. More thoughts on this coming up.

The Takeaways
From my perspective there were three core takeaways:
- Knowledge Graphs/Bases everywhere
- Assume the Web
- Scholarly applications are interesting applications
1. Knowledge Graphs/Bases everywhere
I could call this Entities everywhere. Perhaps, it was the sessions I chose to attend but it felt like when I was at the conference in 2010 where every other paper was about online advertising. There were a ton of papers on entity linking, entity disambiguation, entity (etc.) many others had knowledge base construction as a motivation.

There were two tutorials on knowledge graphs both of them were full and the one from Google/Facebook involved moving to a completely new room. Both were excellent. The one from the Yago team has really good material. As a side note, it was interesting to sit-in on tutorials where I already have a decent handle on the material. It let me compare my own intellectual framework for the material and others out there. For example, I liked the Yago tutorial’s distinction between source-centric and yield-centric information extraction and how we pursue the yield approach when doing automated knowledge base construction. A recommended exercise for the reader.
Beyond just being a plethora of stuff, I think our panel discussion highlighted themes that appeared across several papers.
Dealing with long tail entities
In general, approaches to knowledge base construction have relied on well known entities (e.g. wikipedia) and frequency (you’re mentioned a lot, you’re an entity). For many domain specific entities, for example in science, and also emergent entities this is a challenge. A number of authors tried to tackle this by:
- looking at web page titles as a potential data source for entities (Song et al.)
- use particular types of web tables to help assign entities to classes (Wang et al.)
- use social context help entity extraction (Jie Tang et al. )
- discover new meta relations between entities (Meng et al.)
Quality
All the organizations on the industry panel spend significant resources on quality maintenance of their knowledge graphs. The question here is how to best decrease the amount of human input and increase automation.
An interesting example that was talked about quite frequently is the move of Freebase to Wikidata. Wikidata runs under the same guidelines as Wikipedia so all facts need to have claims grounded in sources from the Web. Well it turns out this is difficult because many facts are sourced from Wikipedia itself. This kind of dare I say it provenance is really important. Most current large scale knowledge graphs support provenance but as we automate more it would be nice to be able to automatically judge these sources using that provenance.
One paper that I saw that addressed quality issues this was GERBIL – General Entity Annotator Benchmarking Framework. This 25 author paper! devised a common framework for testing entity linking tools. It’s great to see the community looking at these sorts of common QA frameworks.
Multimedia
This seemed to be bubbling up. On the panel, the company Tagasauris was looking at constructing a mediaGraph by analyzing video content. During the Yago tutorial, the presenters mentioned potential future work on extracting common sense knowledge by looking at videos. In general, both extraction of facts from multimedia but also using knowledge graphs to understand multimedia seems like a challenging but fruitful area. One particular example was the paper “Tagging Personal Photos with Transfer Deep Learning”. What was cool was the injection of a personal photo ontology into the training of the network as priors. This led to both better results but probably more impotently decreased the training time. Another example is the work from Gerhard Weikum’s group on extracting knowledge from movie scripts.
Finally, as I commented at the Linked Data on the Web Workshop, the growth of knowledge graphs is a triumph of the semantic web and linked data. Making knowledge bases open and available on the Web using reusable schemes has really been a boon to the area.
2. Assume the Web
It’s obvious but is worth repeating: the web is really big!
These stats were from Andrei Broder’s excellent keynote. The size of the web motivates the need for better web technology (e.g. search) and as that improves so do our expectations. Broder called out three axes of progress
- scaling up with quality
- faster response
- higher functionality levels
We progress on all these dimensions. But the scale of the web doesn’t just change the technology we need to develop but it changes our methods.
For example, a paper I liked a lot was “Leveraging Pattern Semantics for Extracting Entities in Enterprises”. This bares resembles towards problems we face extracting entities that are not found on the web because there only mentioned within a private environment (e.g. internal product names). But even in this environment they rely on the Web. They rank semantic patterns they extract by using relations extracted from the web.
For me, it means that even if the application isn’t necessarily for “the web”, I should think about the web as a potential part of the solution.
3 Scholarly applications are interesting applications
I’m biased, but I think scholarly applications are particularly interesting and you saw that at WWW. I attended two workshops dealing with technology and scholarship. SAVE-SD and Big Scholar. I was particularly impressed with the scholarly knowledge graph that’s being built on-top of the Bing Satori Knowledge Graph, which covers venues, authors, papers, and organizations from 100 million papers. (It seems there are probably 120 million total on the web.) At their demo they showed some awesome queries that you can do like: “papers on multiple sclerosis citing artificial intelligence” Another example is venues appearing in the side of bing searches with related venues, due dates, etc:
See Kuansan Wang’s (@kuansanw) talk for more info (slides). As far as I understand, MSR will also be releasing the Microsoft Academic Graph for experimentation in a couple of weeks. Based on this graph MSR is co-organizing with Antonio Gulli from Elsevier the WSDM Cup in 2016
It was a pleasure to meet C. Lee Giles of CiteSeerX. It was good seeing an overview of that system and he had some good pointers (e.g. GROBID for metadata extraction and ParsCit for citation extraction).
From SAVE-SD there were two papers that caught my eye:
- Mapping the evolution of scientific community structures in time
- What’s in this paper? Combining Rhetorical Entities with Linked Open Data for Semantic Literature Querying
There were also a number of main track papers that applied methods to scholarly content.
- Chien looked at extracting semantics from mathematical expressions testing on a web math forums.
- Li et al. looked at algorithms for suggesting a substitute for a particular team member.
- The paper Robust Group Linkage looked at how to identify multiple entities belonging to the same group. For example, restaurants in the same chain, or researchers in the same subarea.
- DiagramFlyer: A Search Engine for Data-Driven Diagrams
Overall, WWW 2015 was a huge event so this trip report really is just what I could touch. I didn’t even get the chance to go to the W3C sessions and Web Science talks. You can check out all the proceedings here, definitely worth a look.
Random thoughts
- The web isn’t scale free – it’s log-log. Gotta check out Clauset et al 2009, Power-law distributions in empirical data
- If you’re a researcher remember that Broder’s “A taxonomy of web search” – was originally rejected from WWW 2002, it now has 1700+ citations.
- Aidan Hogan + 1 for colorful slides and showing that we need to just deal with blank nodes and not get so hung up about it. (paper, code)
- If you do machine learning, do your parameter studies. Most papers had them.
- PROV and information diffusion combined. So awesome.
- Ah conference internet… It’s always hard.
- People are hiring like crazy. Booths from Baidu, Facebook, Yahoo, LinkedIn. Oh, and never discount how frisbee’s can motivate highly educated geeks.
- On the hiring note, I liked how the companies listed their attendees and their talks.
- Tons and tons of talks with authors from companies. I should really do some stats. It was like every paper.
- Italy, food, florentine steak – yummy!
- Corollary, running is necessary but running in Florence is beautiful. Head by the Duomo across the river and up through the gardens.
- What you can do with four square data:
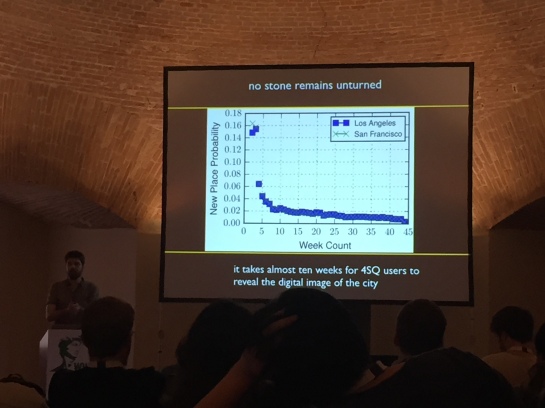
- Larry and Sergei won the test of time award.
- Gotta ask the folks at Insight about their distributional semantics work.

Pingback: Trip Report: SSP 2015 | Think Links
Pingback: Trip Report: SSP 2015 | Web & Media
Pingback: WWW2015: Linked Data or DBpedia? « Linking Research