Trip Report: ISWC 2017
Last week, I conferenced! I attended the 16th International Semantic Web Conference (ISWC 2017) in Vienna at the beginning of the week and then headed up to FORCE 2017 in Berlin for the back half of the week. For the last several ISWC, I’ve been involved in the organizing committee, but this year I got to relax. It was a nice chance to just be an attendee and see what was up. This was made even nicer by the really tremendous job Axel, Jeff and their team did in organizing both the logistics and program. The venues were really amazing and the wifi worked!
Before getting into what I thought were the major themes of the conference, lets do some stats:
- 624 participants
- Papers
- Research track: 197 submissions – 44 accepted – 23% acceptance rate
- In-use: 27 submissions – 9 accepted – 33% acceptance rate
- Resources: 76 submissions – 23 accepted – 30% acceptance rate
- 46 posters & 61 demos
- Over 1000 reviews were done excluding what was done for the workshop / demos / posters. Just a massive amount of work in helping work get better.
This year they expanded the number of best reviewers and I was happy to be one of them:
You can find all the papers online as preprints.
The three themes I took away from the conference were:
- Ecosystems for knowledge engineering
- Learn from everything
- More media
Ecosystems for knowledge engineering
This was a hard theme to find a title for but there were several talks about how to design and engineer the combination of social and technical processes to build knowledge graphs. Deborah McGuinness in her keynote talked about how it took a village to create effective knowledge driven systems. These systems are the combination of experts, knowledge specialists, systems that do ML, ontologies, and data sources. Summed up by the following slide:
My best idea is that this would fall under the rubric of knowledge engineering. Something that has always been part of the semantic web community. What I saw though was the development of more extensive ideas and guidelines about how to create and put into practice not just human focused systems but entire social-techical ecosystems that leveraged all manner of components.
Some examples: Gil et al.’s paper on creating a platform for high-quality ontology development and data annotation explicitly discusses the community organization along with the platform used to enable it. Knoblock et al’s paper on creating linked data for the American Art Collaborative discusses not only the technology for generating linked data from heterogenous sources but the need for a collaborative workflow facilitated by a shared space (Github) but also the need for tools used to do expert review. In one of my favorite papers, Piscopo et al evaluated the the provenance of Wikidata statements and also developed machine learning models that could judge authoritativeness & relevance of potential source material. This could provide a helpful tool in allowing Wikidata editors to garden the statements automatically added by bots. As a last example, Jamie Taylor in his keynote discussed how at Google they have a Knowledge Graph Schema team that is there to support a developers in creating interlocking data structures. The team is focused on supporting and maintaining quality of the knowledge graph.
A big discussion area was the idea coming out of the US for a project / initiative around an Open Knowledge Network introduced by Guha. Again, I’ll put this under the notion of how to create these massive social-technical knowledge systems.
I think more work needs to be done in this space not only with respect to the dynamics of these ecosystems as Michael Lauruhn and I discussed in a recent paper but also from a reuse perspective as Pascal Hitzler has been talking about with ontology design patterns.
Learn from everything
The second theme for me was learning from everything. Essentially, this is the use of the combination of structured knowledge and unstructured data within machine learning scenarios to achieve better results. A good example of this was presented by Achim Rettinger on using cross modal embeddings to improve semantic similarity and type prediction tasks:
Likewise, Nada Lavrač discussed in her keynote how to different approaches for semantic data mining, which also leverages different sources of information for learning. In particular, what was interesting is the use of network analysis to create a smaller knowledge network to learn from.
A couple of other examples include:
- using multiple embeddings to entity alignment across languages;
- using hybrid approaches relying on embeddings and KB search to annotate web tables;
- using global methods for producing RDF embeddings
It’s worth calling out the winner of the renewed Semantic Web Challenge from IBM, which used deep learning in combination with sources such as dbpedia, geonames and background assumptions for relation learning.

Socrates – Winner SWC
(As an aside, I think it’s pretty cool that the challenge was won by IBM on data provided by Thomson Reuters with an award from Elsevier. Open innovation at its best.)
For a more broad take on the complementarity between deep learning and the semantic web, Dan Brickley’s paper is a fun read. Indeed, as we start to potentially address common sense knowledge we will have to take more opportunity to learn from everywhere.
More media
Finally, I think we saw an increase in the number of works dealing with different forms of media. I really enjoyed the talk on Improving Visual Relationship Detection using Semantic Modeling of Scene Descriptions given by Stephan Brier. Where they used a background knowledge base to improve relation prediction between portions of images:
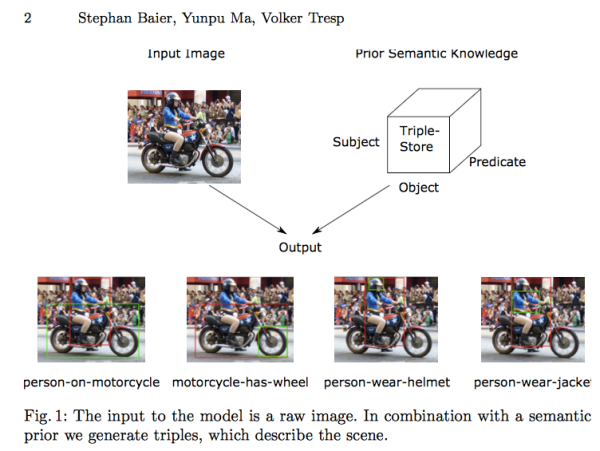
There was entire session focused on multimodal linked data including talks on audio ( MIDI LOD cloud, the Internet Music Archive as linked data) and images IMGPedia content analyzed linked data descriptions of Wikimedia commons. You can even mash-up music with the SPARQL-DJ.
Conclusion
DBpedia won the 10 year award paper. 10 years later semantic technologies and in particular the notion of a knowledge graph are mainstream (e.g. Thomson Reuters has a 100 billion node knowledge graph). While we may still be focused too much on the available knowledge graphs for our research work, it seems to me that the community is branching out to begin to answer a range new questions (how to build knowledge ecosystems?, where does learning fit?, …) about the intersection of semantics and the web.
Random Notes:
- PROV!, PROV (Slide 17)!, PROV!, PROV (pg. 6)!
- Richard Scarry & the future of the knowledge graph.
- Don’t overlook lexicons!
- What I said about ISWC 2016
- Verbs are important. They should rise up 🙂
- Wikipedia is only 5% complete and 15% of Google searches are new everyday
- Identity is hard
- We got some leads at the Job Fair – a good addition
- The LOD can fit on your laptop
- Luminaries debating:
-
- Everybody uses YASGUI
- WInte.r is coming! another cool tool for web data integration from Bizer’s group.
- It’s good to document your ontologies. So use the now award winning WIDOCO.
- SemSci sounded awesome, wish I had made it on time. Interesting to see that science was a big theme last ISWC and now has a reinvigorated workshop. Also Research Objects.
- Impressed with data.world and not just because they sponsored the bar at the ISWC Jam session
- And what a Jam Session!
- My research community is cooler than your research community [1]
- An excellent blockchain paper.
- Nespresso as the default option for coffee is great.
- A coffee challenge is even better.
- Don’t take my word for it. Trip report from: Marieke van Erp, Juan Sequeda
- Olaf & team always impresses by formalizing intuition and providing useful insight. He helped on PROV and now has done it for linked data fragments. A well deserved best paper.
- See you in California next year!

